ClickHouse JIT 源码分析
和 PostgreSQL 一样,ClickHouse 也支持表达式级别的 JIT。但是由于 ClickHouse 是列式存储,具体细节上和 PostgreSQL 有所不同。本文将对 ClickHouse 的 JIT 进行源码分析,从查询计划构建到执行,分析 ClickHouse 是如何利用 LLVM 实现表达式的 JIT 的。
启用 JIT
ClickHouse 中,表达式 JIT 由 core setting compile_expressions 控制,默认是启用的 1。但是,只有当表达式重复执行 min_count_to_compile_expression 次数时才会编译。这里我们把它设置为 0。
在 ClickHouse 中查看和修改设置:
1
2
show settings like 'min_count_to_compile_expression';
set min_count_to_compile_expression = 0;
但这个只对本次会话有效,我们在 users.xml 中将其改为默认设置:
1
2
3
4
5
6
7
8
9
<!-- Profiles of settings. -->
<profiles>
<!-- Default settings. -->
<default>
<min_count_to_compile_expression>0</min_count_to_compile_expression>
</default>
...
</profiles>
表达式 JIT 分析
测试用的 SQL 如下:
1
SELECT a + b * c + 5 FROM test_table;
clickhouse client 是通过 poco 网络库来连接 clickhouse server 的。服务端处理请求的入口函数是 TCPHandler::run。
1
2
3
4
5
TCPHandler::run
└TCPHandler::runImpl
└executeQuery
└executeQueryImpl
└InterpreterSelectWithUnionQuery::execute
executeQueryImpl() 是一个很长的函数,它包含的主要逻辑:
- 对查询语句进行语法解析,生成 AST:
parseQuery() - 获取 interpreter:
InterpreterFactory::get() - 构建查询计划:
res = interpreter->execute()。 - 返回 AST 和类型为
BlockIO的res。
在我们的 SELECT 测试中,获取到的 interpreter 的类型是 InterpreterSelectWithUnionQuery。在 InterpreterSelectWithUnionQuery::execute() 中,首先构建了代表查询步骤树的 QueryPlan。然后调用 QueryPlan 的 buildQueryPipeline 方法构建 QueryPipeline。
简单来说,buildQueryPipeline 方法的作用是:
- 以 DFS 方式遍历
QueryPlan的节点,每遍历到一个节点,就调用node->step->updatePipeline。 updatePipeline最先对叶子节点调用,最后对根节点调用,每次都会返回一个QueryPipelineBuilderPtr。最终,buildQueryPipeline会返回根节点的QueryPipelineBuilderPtr。
在我们的测试用例中,有一个节点的 step 类型是 ExpressionStep。后续流程是:
1
2
ITransformingStep::updatePipeline
└ExpressionStep::transformPipeline
在它的 transformPipeline() 内首先构造 ExpressionActions 对象:
1
auto expression = std::make_shared<ExpressionActions>(actions_dag, settings.getActionsSettings());
其中,actions_dag 是 ExpressionStep 内部指针,指向 ActionsDAG 对象。
在构造函数内,有如下调用:
1
2
3
4
#if USE_EMBEDDED_COMPILER
if (settings.can_compile_expressions && settings.compile_expressions == CompileExpressions::yes)
actions_dag->compileExpressions(settings.min_count_to_compile_expression, lazy_executed_nodes);
#endif
这里的代码使用了 compile_expressions 设置。
然后调用了 ActionsDAG::compileFunctions() 函数。该函数过程比较复杂。
ActionsDAG::compileFunctions() 函数
ActionsDAG 也包含一组节点,和 QueryPlan 内的节点是两个不同的概念。
compileFunctions 方法一开始就为每个节点规定了一些额外的数据:
1
2
3
4
5
6
7
8
9
struct Data
{
bool is_compilable_in_isolation = false;
bool all_parents_compilable = true;
size_t compilable_children_size = 0; // 所有可编译的后代节点数量
size_t children_size = 0; // 所有后代节点数量
};
std::unordered_map<const Node *, Data> node_to_data;
接下来,初始化节点的 is_compilable_in_isolation,这里用到了 IFunction 类的 isCompilable() 接口。
然后,遍历节点直至所有节点标记为已访问。遍历到一个未访问的节点时,如果它的所有子节点都已经访问过了,那么就做如下操作:
- 当前节点的
compilable_children_size赋值为所有子节点的compilable_children_size之和,再加上is_compilable_in_isolation为 true 的子节点的数量。 - 当前节点的
children_size赋值为所有子节点的children_size之和,再加上子节点数量。 - 将当前节点标记为已访问。
接着,设置每个节点的 all_parents_compilable:
- 当所有父节点(可能有多个)的
is_compilable_in_isolation为 true,compilable_children_size大于 0 时,设置all_parents_compilable为 true,否则设置为 false。 - 标记为 output 的节点的
all_parents_compilable强制为假。
最后,确定哪些节点是真正可编译的,要求是:
is_compilable_in_isolation为真;compilable_children_size大于 0;all_parents_compilable为假。(如果所有父节点都可以编译,那就没有必要独立编译)
按照子节点数量排序得到的可编译节点集合。子节点数量多的节点会先被编译,避免子表达式在父表达式编译前被编译了。
对排序好的节点开始遍历,首先会调用 getCompilableDAG 获得一个类型为 CompileDAG 的 dag 对象。在这个新的 DAG 中,有三类节点:INPUT, CONSTANT, FUNCTION。如下图所示,本例中一共三个 INPUT 节点,一个 CONSTANT 节点,三个 FUNCTION 节点。

然后调用:
1
auto fn = compile(dag, min_count_to_compile_expression)
返回的 fn 用于更新 ActionDAG 节点信息:
1
2
3
4
5
6
node->type = ActionsDAG::ActionType::FUNCTION;
node->function_base = fn;
node->function = fn->prepare(arguments);
node->children.swap(new_children);
node->is_function_compiled = true;
node->column = nullptr;
compile() 函数
compile() 函数首先使用了 ClickHouse 的设置参数 min_count_to_compile_expression。如果发现该 DAG 运行次数小于 min_count_to_compile_expression,就不再编译,返回空指针。
然后,compile() 以 CompileDAG 的 dag 为参,创建了一个 LLVMFunction 对象。该 LLVMFunction 对象的 name 成员变量很重要,后续创建 LLVM 的函数名就使用了这个 name。
name 的值赋为 dag.dump(),在我们的例子里为 "plus(plus(Int32, multiply(Int32, Int32)), 5 : UInt8)"。
1
2
3
4
5
6
7
8
9
class LLVMFunction : public IFunctionBase {
...
private:
std::string name; // 函数名称,后续用到 LLVM 函数上
CompileDAG dag;
DataTypes argument_types;
std::vector<FunctionBasePtr> nested_functions;
std::shared_ptr<CompiledFunctionHolder> compiled_function_holder;
};
构造时,用 FUNCTION 节点初始化了 nested_functions,用 INPUT 节点初始化了 argument_types。
ClickHouse 会缓存编译的函数,由 dag 的哈希值判断是否在缓存里,如果在,就直接用缓存的函数设置 compiled_function_holder,然后返回 LLVMFunction 对象。
否则,将调用 compileFunction() 编译函数:
1
auto compiled_function = compileFunction(getJITInstance(), *llvm_function);
返回值 compiled_function 用来设置 compiled_function_holder。
接下来的流程:
1
2
3
4
5
compileFunction(CHJIT&, const IFunctionBase&)
└CHJIT::compileModule
├createModuleForCompilation
├compileFunction(llvm::Module&, const IFunctionBase&)
└compileModule
CHJIT::compileModule 返回了已编译的模块的信息,compileFunction(CHJIT&, const IFunctionBase&) 紧接着这些信息中获取到函数地址,然后返回。
注意,这里用到的 CHJIT 是 ClickHouse 利用 OrcJIT API 自定义的 JIT 类,采用单例模式工作,其内部包含了一个 llvm::LLVMContext 类型的 context 成员。
而在 CHJIT::compileModule 中,首先就是用 jit 对象内的 context 创建了 llvm::Module。然后 compileFunction(llvm::Module&, const IFunctionBase&) 调用向 Module 中添加了函数。而 compileModule 则负责将 Module 编译成机器码,并建立一个函数名称与函数地址的映射关系。
下面分析是如何添加函数的。
compileFunction(llvm::Module&, const IFunctionBase&) 函数
compileFunction(llvm::Module&, const IFunctionBase&) 的流程如下:
首先,在这里创建一个 LLVM 函数。函数名为 "plus(plus(Int32, multiply(Int32, Int32)), 5 : UInt8)"。函数类型为 void (int64_t rows_count_arg, struct data* columns_arg),其中 struct data { int8_t*, int8_t* }。
这里的 rows_count_arg 是行数,columns_arg 是一个结构体,包含了列数据指针。
然后,添加 entry 块,设置指令插入点。
获取 LLVMFunction 对象的 argument_types,这是之前拿 CompileDAG 的 INPUT 类型节点初始化的。获取 CompileDAG 的结果类型。它们都是和某个列数据相关,我们在 entry 块中创建相关语句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct ColumnDataPlaceholder
{
/// Pointer to column raw data
llvm::Value * data_ptr = nullptr;
/// Data type of column raw data element
llvm::Type * data_element_type = nullptr;
/// Pointer to null column raw data. Data type UInt8
llvm::Value * null_data_ptr = nullptr;
};
std::vector<ColumnDataPlaceholder> columns(function_argument_types.size() + 1);
for (size_t i = 0; i <= function_argument_types.size(); ++i)
{
const auto & function_argument_type = i == function_argument_types.size() ? function.getResultType() : function_argument_types[i];
auto * data = b.CreateLoad(data_type, b.CreateConstInBoundsGEP1_64(data_type, columns_arg, i));
columns[i].data_ptr = b.CreateExtractValue(data, {0});
columns[i].data_element_type = toNativeType(b, removeNullable(function_argument_type));
columns[i].null_data_ptr = function_argument_type->isNullable() ? b.CreateExtractValue(data, {1}) : nullptr;
}
接下来,我们创建循环指令,在循环内,包含如下指令:
- 从
columns[i].data_ptr中加载数据的指令,赋值为arguments。 - 调用
function.compile(..., arguments),实际调用的是CompileDAG::compile方法。在处理 DAG 时,对FUNCTION类型的节点,调用了它的函数的IFunction::compile方法,最后是调用了FunctionBinaryArithmetic::compileImpl。 - 创建指令将 DAG 计算结果 store 到结果列中。
- 循环次数达到
rows_count_arg行数时,跳出循环。
在 FunctionBinaryArithmetic::compileImpl 函数内,会调用操作符的 compile 方法。比如,如果是 plus 操作符,就会调用 PlusImpl::compile 方法:
1
2
3
4
5
// in struct PlusImpl
static inline llvm::Value * compile(llvm::IRBuilder<> & b, llvm::Value * left, llvm::Value * right, bool)
{
return left->getType()->isIntegerTy() ? b.CreateAdd(left, right) : b.CreateFAdd(left, right);
}
至此,我们创建了一个 LLVM 函数,它循环所有输入列的数据,应用表达式的计算,将结果存在结果列,最后返回 void。
何时调用已编译函数?
在前面,我们已经将表达式对应的 LLVM 函数编译成了机器码,并将其地址存在了 ActionDAG 节点中。那么,何时调用这个函数呢?
transformPipeline() 内, 构造 ExpressionActions 结束后:
1
2
3
4
5
6
auto expression = std::make_shared<ExpressionActions>(actions_dag, settings.getActionsSettings());
pipeline.addSimpleTransform([&](const Block & header)
{
return std::make_shared<ExpressionTransform>(header, expression);
});
执行引擎在执行查询时需要对 a + b * c + 5 表达式求值。在物理查询计划中,此步骤就称为 ExpressionTransform 。而在 ExpressionTransform 的构造过程中,调用了 LLVM 函数:
1
2
3
4
5
6
7
8
9
ExpressionTransform::ExpressionTransform
└ExpressionTransform::transformHeader
└ActionsDAG::updateHeader
└executeActionForHeader
└IExecutableFunction::execute
└IExecutableFunction::executeWithoutSparseColumns
└IExecutableFunction::executeWithoutLowCardinalityColumns
└IExecutableFunction::executeDryRunImpl
└LLVMExecutableFunction::executeImpl
其中,LLVMExecutableFunction 就是之前保存在 ActionDAG 的节点内的信息之一。在 LLVMExecutableFunction::executeImpl 内,最终调用 LLVM 函数:
1
2
auto jit_compiled_function = compiled_function_holder->compiled_function.compiled_function;
jit_compiled_function(input_rows_count, columns.data());
ClickHouse JIT 总结
根据分析结果,可以画出下面的流程图:
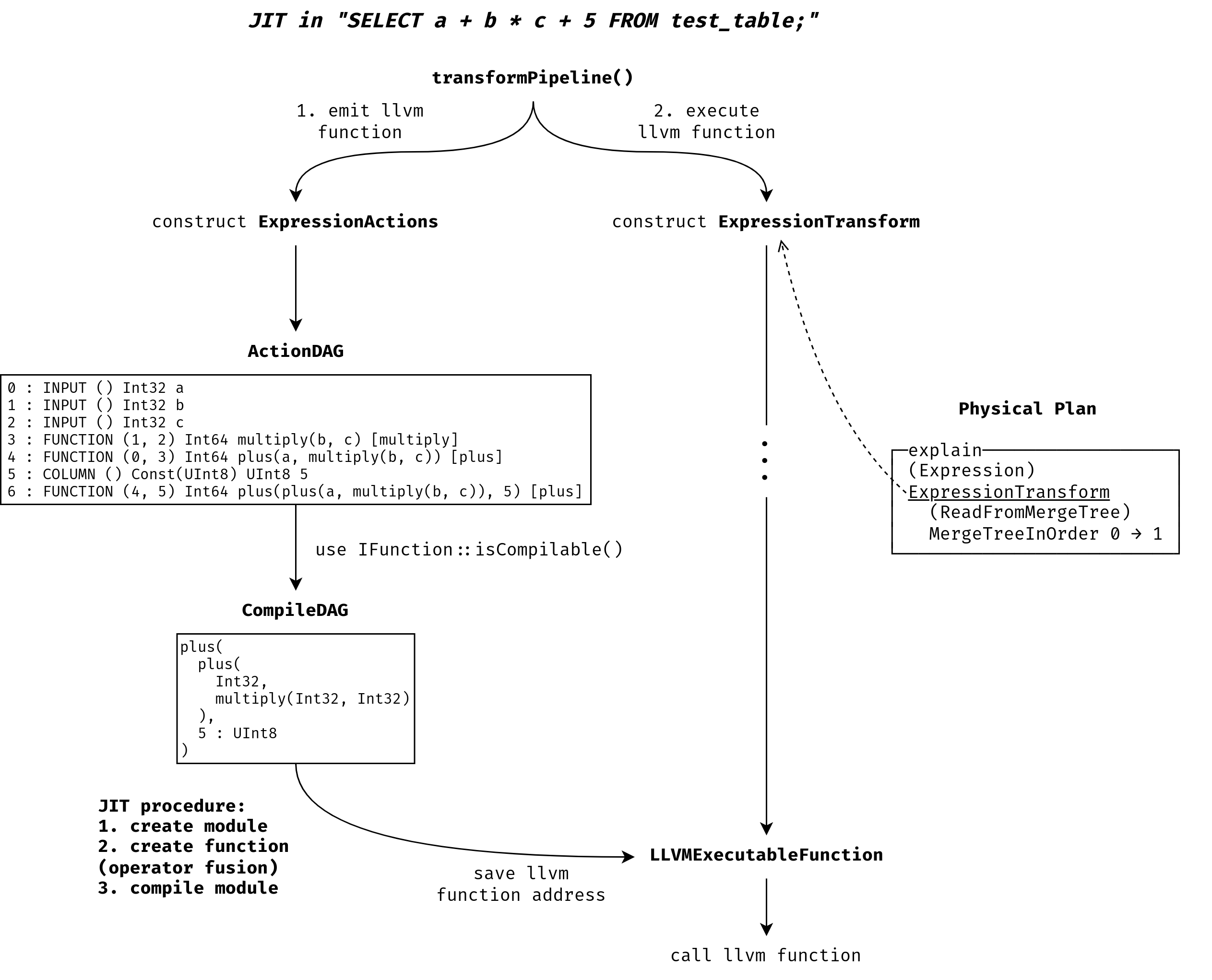
ClickHouse 的表达式编译是在创建 QueryPipeline 时构造 ExpressionActions 对象时进行的。CH 会首先判断表达式 DAG (ActionDAG) 中哪些内容可以编译,因为并不是所有表达式节点都可以被编译。针对任何适合编译的表达式子图 (CompileDAG),CH 会添加一个统一的 LLVM 函数,它的参数是行数和列数据指针。该函数主体是一个循环,循环内对每一行数据应用表达式计算(plus, multiply 等),将结果存入结果列中。然后 CH 将函数所在的 Module 都编译为机器码,并将编译后的函数地址保存。
ClickHouse 与 PostgreSQL 的 JIT 分析:
- CH 的 JIT 与项目其他组件耦合度更高,大部分函数内都要实现 JIT 相关逻辑。而 PG 则将 JIT 单独作为共享库发布,与 PG 本身解耦。
- CH 的 LLVM 函数的创建和编译都发生在构建 Pipeline 过程中,而 PG 则是先在构建查询计划时创建 LLVM 函数,然后在执行查询时编译。
- 由于 CH 是列式存储,CH 的 LLVM 函数内部是一个循环,一次性处理完所有列数据。而 PG 的 LLVM 函数一次只处理一行数据。
- CH 内部会分析表达式的 DAG,判断哪些可以编译,并尽可能地将多个算子融合编译,让数据尽可能地留在寄存器内。PG 未测试相关用例,但应该也有这个能力(多个
ExprEvalStep一起编译)。
总地来说,CH 的 JIT 实现得更加复杂,但也更为合理和先进,能充分利用 JIT 的好处,加速列数据的处理。
Comments